

Bei der Berechnung potenzieller Verluste durch Cyber-Risiken sind statistische Daten ebenso wichtig wie ihre Interpretationen. Die Experten von Kaspersky kommentieren einen Beitrag der Black Hat 2020-Konferenz.
Niemand will mehrere Millionen für den Schutz eines Unternehmens ausgeben, wenn der tatsächliche Schaden im Falle eines Vorfalls die mehreren Tausend nicht übersteigen würde. Genauso unsinnig sind Kosteneinsparungen, indem man an allen Ecken spart, wenn der potenzielle Schaden eines Datenlecks mehrere Hunderttausende betragen könnte. Aber welche Informationen sollten man für die Berechnung des ungefähren Schadens, den ein Unternehmen durch einen Cyber-Zwischenfall erleiden würde, verwenden? Und wie schätzt man die tatsächliche Wahrscheinlichkeit eines solchen Vorfalls ein? Auf der Black Hat 2020-Konferenz präsentierten zwei Forscher, Professor Wade Baker von Virginia Tech und David Seversky, ein leitender Analyst des Cyentia-Institute, ihren Standpunkt in Sachen Risikobewertung. Ihre Argumente sind einer näheren Betrachtung durchaus wert.
Jeder hochwertiger Cybersicherheitskurs lehrt, dass die Risikobewertung von zwei Hauptfaktoren abhängt: der Wahrscheinlichkeit eines Vorfalls und seinen potenziellen Verlusten. Aber woher kommen diese Daten und, was noch wichtiger ist, wie sollten sie interpretiert werden? Schließlich führt die Einschätzung möglicher Verluste fälschlicherweise zu fehlerhaften Schlussfolgerungen, die wiederum nicht optimierte Schutzstrategien zufolge haben.
Ist das arithmetische Mittel ein brauchbarer Indikator?
Viele Unternehmen führen Studien über mögliche finanzielle Verluste wegen Datenpannen durch. Ihre „Hauptergebnisse“ sind in der Regel Durchschnittswerte der Verluste von Unternehmen vergleichbarer Größe. Das Ergebnis ist mathematisch gültig und die Zahl kann in eingängigen Schlagzeilen großartig wirken, aber kann man sich bei der Berechnung von Risiken wirklich darauf verlassen?
Stellt man dieselben Daten in einem Diagramm dar (Gesamtverluste entlang der horizontalen Achse; Anzahl der Vorfälle entlang der vertikalen Achse), wird deutlich, dass das arithmetische Mittel nicht der richtige Indikator ist. Bei 90% der Vorfälle liegen die durchschnittlichen Verluste unter dem arithmetischen Mittel.
Verlustbewertung durch verschiedene Indikatoren
Wenn man über die Verluste spricht, die ein durchschnittliches Unternehmen erleiden kann, dann ist es sinnvoller, andere Indikatoren zu betrachten, insbesondere den Median (die Zahl, die die Stichprobe in zwei gleiche Teile teilt, so dass die Hälfte der gemeldeten Zahlen höher und die Hälfte niedriger ist) und den geometrischen Mittelwert (einen proportionalen Durchschnitt). Die meisten Unternehmen erleiden genau solche Verluste. Der arithmetische Mittelwert kann aufgrund einer kleinen Anzahl von Vorfällen mit ungewöhnlich hohen Verlusten eine sehr verwirrende Zahl ergeben.
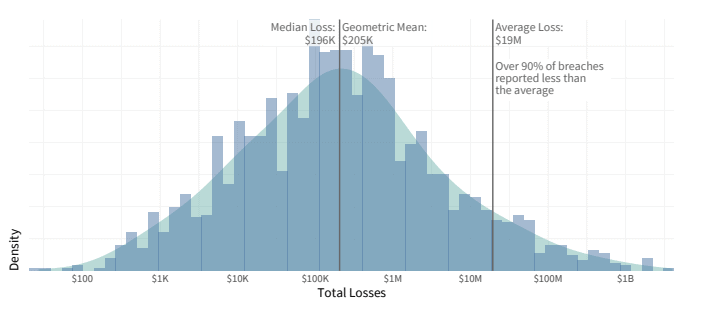
Verteilung von Datenpannen-Verlusten. Quelle: Studie cyentia.com “Information Risk Insights Study – IRIS 2020”
Durchschnittliche Kosten einer Datenpanne
Ein weiteres Beispiel für einen fragwürdigen „Durchschnitt“ ergibt sich aus der Methode zur Berechnung von Datenpannen-Verluste, bei der die Anzahl der betroffenen Datensätze mit dem durchschnittlichen Schadensbetrag resultierend aus dem Verlust eines Datensatzes multipliziert wird. Die Praxis hat gezeigt, dass diese Methode die Verluste kleiner Vorfälle unterschätzt und die Verluste großer Vorfälle stark überschätzt.
Ein Beispiel: Vor einiger Zeit verbreitete sich auf vielen Analyseseiten eine Meldung, in der behauptet wurde, dass falsch konfigurierte Cloud-Dienste Unternehmen fast 5 Billionen Dollar gekostet hätten. Wenn man recherchiert, woher dieser astronomische Betrag stammte, wird klar, dass die Zahl von 5 Billionen Dollar allein dadurch zustande kam, dass man die Anzahl der „geleakten“ Datensätze mit dem durchschnittlichen Schaden durch den Verlust eines Datensatzes (150 Dollar) multiplizierte. Letztere Zahl stammt aus der 2019 vom Ponemon-Institut durchgeführten Studie über die Kosten einer Datenpanne.
Arithmetische Mittel geben nicht immer klare Auskunft über die Verluste
Die Geschichte sollte jedoch mit einigen Vorbehalten betrachtet werden. Zunächst einmal berücksichtigte die Studie nicht alle Vorfälle. Zweitens gibt das arithmetische Mittel keine klare Auskunft über die Verluste, selbst wenn man nur die verwendete Stichprobe betrachtet. Es wurden nur Fälle berücksichtigt, deren Verlust einen Schaden von weniger als 10.000 Dollar und mehr als 1 Cent verursachen würde. Darüber hinaus geht aus der Methodik der Studie klar hervor, dass der Mittelwert für Vorfälle, bei denen mehr als 100.000 Datensätze betroffen waren, nicht gültig ist. Daher war es grundlegend falsch, die Gesamtzahl der Datensätze, die aufgrund falsch konfigurierter Cloud-Dienste geleakt wurden, mit 150 zu multiplizieren.
Wenn diese Methode zu einer echten Risikobewertung führen soll, muss sie einen weiteren Indikator für die Wahrscheinlichkeit von Verlusten in Abhängigkeit vom Ausmaß des Vorfalls enthalten.
Der Dominoeffekt
Ein weiterer Faktor, der bei der Berechnung der Schäden eines Vorfalls oft übersehen wird, ist die Kettenreaktion solcher modernen Datenpannen, die mehr als nur ein einzelnes Unternehmen betrifft. In vielen Fällen übersteigt der Gesamtschaden, der von Drittfirmen (Partnern, Auftragnehmern und Lieferanten) verursacht wird, den Schaden für das Unternehmen, von dem die Daten durchgesickert sind.
Die Zahl solcher Vorfälle nimmt von Jahr zu Jahr zu, da der allgemeine Trend zur „Digitalisierung“ den Grad der gegenseitigen Abhängigkeit von Geschäftsprozessen in verschiedenen Unternehmen erhöht. Den Ergebnissen der von RiskRecon und Cyentia durchgeführten Studie zufolge, sorgten 813 Vorfälle dieser Art bei 5.437 Organisationen und Unternehmen zu Verlusten. Das bedeutet, dass von jedem Unternehmen, das eine Datenpanne erlitten hat, im Durchschnitt mehr als vier Unternehmen von dem Vorfall betroffen sind.
Praxistipps
Zusammenfassend lässt sich sagen, dass vernünftige Experten, die Cyberrisiken einschätzen, den folgenden Ratschlag beherzigen sollten:
- Trauen Sie auffälligen Schlagzeilen nicht. Auch wenn viele Websites bestimmte Informationen enthalten, sind sie nicht unbedingt richtig. Schauen Sie immer auf die Quelle, die die Behauptung untermauert, und analysieren Sie die Methodik der Forscher selbst.
- Verwenden Sie nur Forschungsergebnisse, die Sie inhaltlich nachvollziehen können und im Einklang mit Ihrer Risikobewertung stehen.
- Denken Sie daran, dass ein Vorfall in Ihrem Unternehmen zu Datenpannen für andere Unternehmen führen kann. Wenn ein Leak entstehen sollte, für das Ihr Unternehmen verantwortlich ist, werden die anderen Parteien wahrscheinlich rechtliche Schritte gegen Sie einleiten, wodurch sich Ihr Schaden durch den Vorfall erhöht.
- Vergessen Sie auch den konträren Fall nicht. Datenpannen bei Partnern, Lieferanten und Auftragnehmer, die Sie in keinster Weise beeinflussen können, können Ihre Daten auch leaken.
Mehr dazu im Blog bei Kaspersky.com
Über Kaspersky Kaspersky ist ein internationales Cybersicherheitsunternehmen, das im Jahr 1997 gegründet wurde. Die tiefgreifende Threat Intelligence sowie Sicherheitsexpertise von Kaspersky dient als Grundlage für innovative Sicherheitslösungen und -dienste, um Unternehmen, kritische Infrastrukturen, Regierungen und Privatanwender weltweit zu schützen. Das umfassende Sicherheitsportfolio des Unternehmens beinhaltet führenden Endpoint-Schutz sowie eine Reihe spezialisierter Sicherheitslösungen und -Services zur Verteidigung gegen komplexe und sich weiter entwickelnde Cyberbedrohungen. Über 400 Millionen Nutzer und 250.000 Unternehmenskunden werden von den Technologien von Kaspersky geschützt. Weitere Informationen zu Kaspersky unter www.kaspersky.com/