

Es herrscht ein großer Hype um den Einsatz von künstlicher Intelligenz (KI) in der Cybersecurity. Die Wahrheit ist, dass sich Rolle und Potenzial von KI im Bereich Sicherheit noch in der Entwicklung befinden und noch vieles erforscht und evaluiert werden muss. ein Kommentar von Chester Wisniewski, Principal Research Scientist, Sophos.
Um die KI möglichst schnell weiterzuentwickeln und um sie noch effizienter in der Security einsetzen zu können, ist der übergreifende Austausch zwischen Forschern und KI-Experten besonders wichtig. Aus diesem Grund hat sich Sophos AI dazu verpflichtet, seine Forschungsergebnisse offen mit der Sicherheits-Community zu teilen, um den Einsatz von KI transparenter zu gestalten und um zur Diskussion und Positionierung von KI in der Cybersecurity aktiv beizutragen. Eines der wichtigsten Themen in der Weiterentwicklung von KI in der Cybersicherheit sind die unterschiedlichen Modelle und Methoden, wie die KI mit alten und neuen Daten lernt.
„Katastrophales Vergessen“ als KI-Erkennungsmodell
Die Malware-Erkennung ist der Eckpfeiler der IT-Sicherheit und KI ist der einzige Ansatz, der innerhalb weniger Tage Muster aus Millionen neuer Malware-Samples erlernen kann. Beim Einsatz von KI zur Malware-Erkennung treten allerding zwei Fragen auf: Soll das Modell alle Malware-Samples für immer behalten, um eine optimale Erkennung zu ermöglichen – allerdings auf Kosten der Lern- und Aktualisierungsgeschwindigkeit? Oder soll es eine selektive Feinabstimmung vornehmen, die es dem Modell ermöglicht, besser mit der Änderungsrate von Malware Schritt zu halten – allerdings mit dem Risiko, ältere Muster zu vergessen? Letzteres ist bekannt als „katastrophales Vergessen“. Heute dauert das Neutrainieren eines Modells etwa eine Woche. Die Aktualisierung eines guten Fine-Turning-Modells nimmt etwa eine Stunde in Anspruch.
Das Sophos-AI-Team wollte herausfinden, ob es möglich ist, ein Feinabstimmungsmodell zu designen, das mit der schnellen Entwicklung der Bedrohungslandschaft Schritt hält, neue Muster lernt, sich aber dennoch an ältere Samples erinnert und dabei minimale Auswirkungen auf die Leistung hat. Dieser Aufgabe hat sich die Forscherin Hillary Sanders angenommen und eine Reihe von Update-Optionen evaluiert, die sie im Sophos AI Blog detailliert beschriebt.
Das Dilemma der Erkennung
Die Malware-Erkennung auf dem neuesten Stand zu halten, ist keine leichte Aufgabe. Jeden Schritt, den man zur Abwehr eines Angriffs unternimmt, quittieren die Gegner mit neuen Ideen, diesen zu umgehen. Sie entwickeln Updates mit anderem Code oder anderen Techniken. Das Resultat: Jeden Tag tauchen Hunderttausende neuer Malware-Samples auf.
Erschwert wird die Erkennung zusätzlich durch die Tatsache, dass die neueste und wirksamste Malware selten völlig „neu“ ist. Oft handelt es sich um eine Kombination aus neuem, altem, gemeinsam genutztem, geliehenem oder gestohlenem Code sowie übernommenen und angepassten Verhaltensweisen. Zudem taucht alte Malware auch nach Jahren wieder auf und wird in neue Angriffsmethoden integriert, um die Abwehr zu überrumpeln. Ergo müssen Erkennungsmodelle sicherstellen, dass sie auch ältere Malware-Samples erkennen, und nicht nur die neuesten.
Aktualisierung von KI-Erkennungsmodellen
Wenn es darum geht, KI-Erkennungsmodelle mit neuen Malware-Samples zu aktualisieren, haben Anbieter die Wahl zwischen zwei Optionen.
Option1: Das Aufbewahren jedes einzelnen Samples und das wiederkehrende Neu-Trainieren des Modells mit immer größeren Datenmengen. Dies führt zu einer besseren Gesamtperformance, aber auch zu langsameren Updates und weniger Releases.
Option 2: Das Erkennungsmodell wird nur mit neuen Samples aktualisiert. Dies wird als Feintuning bezeichnet. Bei jedem Schritt des Feinabstimmungsprozesses aktualisiert sich das Modell mit dem neu hinzugefügten Wissen und mit den Auswirkungen auf alle verfügbaren Muster. Infolgedessen kann das Modell die alten Muster, die es zuvor gelernt hat, „vergessen“ („katastrophales Vergessen“). Der Vorteil: Das Trainieren eines Modells mit weniger Daten hat zur Folge, dass es schneller aktualisiert und bereitgestellt werden kann, um besser mit der schnellen Veränderung von Malware Schritt zu halten.
Kontinuierliches trainieren der KI-Erkennungsmodelle
Unabhängig von den beiden genannten Optionen ist das kontinuierliche trainieren der KI-Erkennungsmodelle mit neuen Samples entscheidend. Denn die Muster, die eine KI aus Malware-Samples erlernt, ermöglichen eine Erkennung nicht nur in Bezug auf das unmittelbar trainierte. Die KI erkennt auch bisher unbekannte Samples, die zumindest eine gewisse Ähnlichkeit mit den Trainingsdaten aufweisen. Allerdings weichen im Laufe der Zeit neue Samples so weit ab, dass die Effektivität eines alten Modells nachlässt und es aktualisiert werden muss.
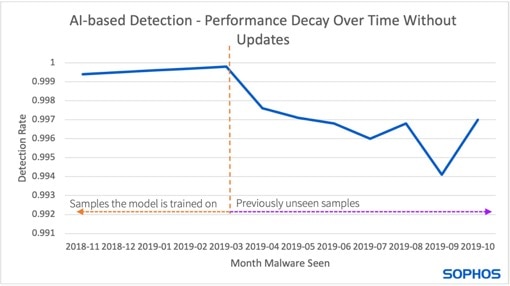
Das Diagramm zeigt, wie die Erkennungsleistung im Laufe der Zeit abnimmt, wenn die Modelle nicht aktualisiert werden (Bild: Sophos).
Die linke Seite des Diagramms (neben der gestrichelten Linie) zeigt das Modell auf der Zeitachse mit den älteren trainierten Samples. Hier ist die Erkennungsrate konstant hoch. Auf der rechten Seite kommen neue Samples hinzu, auf die das Modell noch nicht trainiert wurde, was eine geringere Erkennungsrate zur Folge hat.
Drei Optionen zur Aktualisierung der Malware-Erkennung
Die drei Optionen zur Aktualisierung der Erkennung von Malware, die von Hillary Sanders bewertet wurden, sind:
1. Lernen mit einer Auswahl von alten und neuen Proben
Dies wird als „Data-Rehearsal“ bezeichnet und beinhaltet eine kleine Auswahl alter Proben, die mit den neuen, noch nie zuvor gesehenen Trainingsdaten gemischt werden. Auf diese Weise wird das Modell an die alten Informationen „erinnert“, die es zur Erkennung älterer Muster benötigt, während es gleichzeitig lernt, die neueren zu erkennen.
2. Justieren der Lerngeschwindigkeit
Bei diesem Ansatz wird die Lerngeschwindigkeit des Modells angepasst. Dies wird durch die Definition, wie stark sich das Modell nach dem Sehen einer bestimmten Probe ändern kann, erreicht. Wenn die Lernrate zu schnell ist (in diesem Fall kann sich das Modell mit jeder hinzugefügten Probe stark verändern), merkt es sich nur die letzten Proben. Wenn die Lernrate zu langsam ist (das Modell kann sich mit jeder hinzugefügten Stichprobe nur geringfügig ändern), dauert es zu lange, bis es etwas lernt. Die Schwierigkeit ist den perfekten Kompromiss zwischen Lernrate, Beibehaltung alter Informationen und Hinzufügen neuer Informationen zu finden.
3. Elastic Weight Consolidation (EWC)
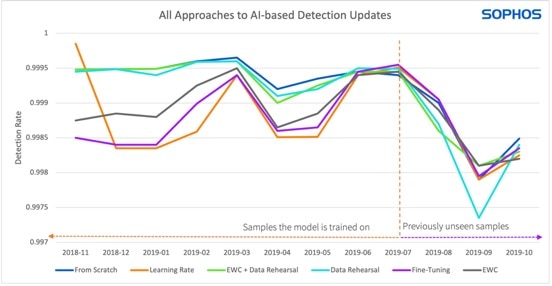
Im Diagramm schneiden alle drei Ansätze bei älteren Malware-Samples (links der gestrichelten Linie) besser ab als bei neueren Samples – rechts der gestrichelten Linie (Bild: Sophos).
Dieser Ansatz wurde durch die Arbeit von Googles DeepMind im Jahr 2017 inspiriert. Wie eine elastische Feder zieht es ein neues Modell auf ein älteres zurück, sollte es beginnen zu „vergessen“. Eine ausführlichere Beschreibung dieses Prinzips hat Hillary Sanders auf dem Sophos AI Blog veröffentlicht.
Im Diagramm dargestellt schneiden alle drei Ansätze bei älteren Malware-Samples (links der gestrichelten Linie) besser ab als bei neueren Samples (rechts der gestrichelten Linie).
Fazit
Das Lernen mit einer Auswahl von alten und neuen Proben (Data-Rehearsal) ist der beste Kompromiss
Bei der Malware-Erkennung ist die Fähigkeit, sich an Vergangenes zu erinnern, fast genauso wichtig wie die Fähigkeit, die Zukunft vorherzusagen. Dies muss allerdings gegen die Kosten und die Geschwindigkeit der Aktualisierung des Modells mit neuen Informationen abgewogen werden. Data-Rehearsal ist eine einfache und effektive Methode, um die Erkennung alter Malware aufrechtzuerhalten und gleichzeitig die Geschwindigkeit, mit der man neue Modelle aktualisieren und veröffentlichen kann, deutlich zu erhöhen.
Mehr dazu bei Sophos.com
Über Sophos Mehr als 100 Millionen Anwender in 150 Ländern vertrauen auf Sophos. Wir bieten den besten Schutz vor komplexen IT-Bedrohungen und Datenverlusten. Unsere umfassenden Sicherheitslösungen sind einfach bereitzustellen, zu bedienen und zu verwalten. Dabei bieten sie die branchenweit niedrigste Total Cost of Ownership. Das Angebot von Sophos umfasst preisgekrönte Verschlüsselungslösungen, Sicherheitslösungen für Endpoints, Netzwerke, mobile Geräte, E-Mails und Web. Dazu kommt Unterstützung aus den SophosLabs, unserem weltweiten Netzwerk eigener Analysezentren. Die Sophos Hauptsitze sind in Boston, USA, und Oxford, UK.