

Al calcular las pérdidas potenciales de los riesgos cibernéticos, los datos estadísticos son tan importantes como su interpretación. Los expertos de Kaspersky comentan una publicación de la conferencia Black Hat 2020.
Nadie quiere gastar millones para proteger una empresa si el daño real en caso de incidente no supera los miles. Igualmente inútil es reducir costos tomando atajos cuando el daño potencial de una fuga de datos podría ser de cientos de miles. Pero, ¿qué información se debe utilizar para calcular el daño aproximado que sufriría una empresa por un incidente cibernético? ¿Y cómo evalúa la probabilidad real de tal incidente? En la conferencia Black Hat 2020, dos investigadores, el profesor Wade Baker de Virginia Tech y David Seversky, analista sénior del Instituto Cyentia, presentaron su perspectiva sobre la evaluación de riesgos. Vale la pena examinar sus argumentos.
Cualquier curso de ciberseguridad de calidad enseña que la evaluación de riesgos depende de dos factores principales: la probabilidad de un incidente y sus pérdidas potenciales. Pero, ¿de dónde provienen estos datos y, lo que es más importante, cómo deben interpretarse? Después de todo, la evaluación incorrecta de posibles pérdidas conduce a conclusiones erróneas, que a su vez dan como resultado estrategias de protección no optimizadas.
¿Es la media aritmética un indicador útil?
Muchas empresas realizan estudios sobre posibles pérdidas financieras debido a violaciones de datos. Sus "resultados principales" suelen ser promedios de las pérdidas de empresas de tamaño comparable. El resultado es matemáticamente válido y el número puede verse muy bien en titulares pegadizos, pero ¿realmente se puede confiar en él para calcular el riesgo?
Trazar los mismos datos en un gráfico (pérdidas totales a lo largo del eje horizontal; número de incidentes a lo largo del eje vertical) muestra que la media aritmética no es el indicador correcto. En el 90% de los incidentes, las pérdidas promedio están por debajo de la media aritmética.
Evaluación de pérdidas por varios indicadores
Cuando se habla de las pérdidas en las que puede incurrir una empresa promedio, tiene más sentido mirar otros indicadores, particularmente la mediana (el número que divide la muestra en dos partes iguales, de modo que la mitad de los números informados son más altos y la otra mitad es menor) y la media geométrica (un promedio proporcional). La mayoría de las empresas sufren tales pérdidas. La media aritmética puede ser un número muy confuso debido a una pequeña cantidad de incidentes con pérdidas inusualmente altas.
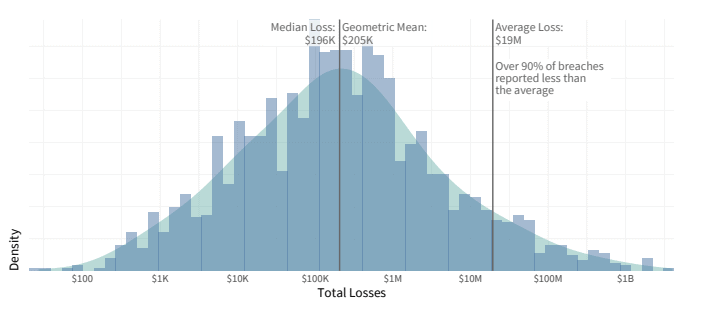
Distribución de las pérdidas por violación de datos. Fuente: estudio de cyentia.com “Estudio de información sobre riesgos de la información – IRIS 2020”
Costo promedio de una violación de datos
Otro ejemplo de un "promedio" cuestionable proviene del método de cálculo de pérdida por violación de datos, que multiplica la cantidad de registros afectados por la cantidad promedio de daño resultante de la pérdida de un registro. La práctica ha demostrado que este método subestima las pérdidas de pequeños incidentes y sobreestima en gran medida las pérdidas de grandes incidentes.
Un ejemplo: Hace un tiempo, circuló una historia en muchos sitios de análisis que afirmaba que los servicios en la nube mal configurados habían costado a las empresas casi $ 5 billones. Al investigar de dónde provino esta cantidad astronómica, queda claro que se llegó a la cifra de $ 5 billones simplemente multiplicando la cantidad de registros "filtrados" por el daño promedio causado por la pérdida de un registro ($ 150). El último número proviene del estudio del Instituto Ponemon de 2019 sobre el costo de una violación de datos.
Las medias aritméticas no siempre proporcionan información clara sobre las pérdidas
Sin embargo, la historia debe verse con algunas reservas. En primer lugar, el estudio no consideró todos los incidentes. En segundo lugar, la media aritmética no da una indicación clara de las pérdidas, incluso cuando se observa únicamente la muestra utilizada. Solo se consideraron los casos cuya pérdida causaría un daño de menos de $10.000 y más de 1 centavo. Además, la metodología del estudio deja claro que la media no es válida para incidentes que involucren más de 100.000 registros. Por lo tanto, multiplicar el número total de registros filtrados debido a servicios en la nube mal configurados por 150 fue fundamentalmente incorrecto.
Para que este método resulte en una verdadera evaluación de riesgos, debe incluir otro indicador de la probabilidad de pérdidas dependiendo de la magnitud del incidente.
El efecto dominó
Otro factor que a menudo se pasa por alto al calcular el daño de un incidente es la reacción en cadena de tales violaciones de datos modernas, que afectan a más de una sola organización. En muchos casos, el daño general causado por empresas de terceros (socios, contratistas y proveedores) supera el daño a la empresa de la que se filtraron los datos.
El número de tales incidentes aumenta cada año a medida que la tendencia general hacia la "digitalización" aumenta el grado de interdependencia de los procesos comerciales en diferentes empresas. Según los resultados del estudio realizado por RiskRecon y Cyentia, 813 incidentes de este tipo generaron pérdidas para 5.437 organizaciones y empresas. Esto significa que por cada empresa que sufre una filtración de datos, en promedio más de cuatro empresas se ven afectadas por el incidente.
Consejos prácticos
En resumen, los expertos sensatos que evalúan los riesgos cibernéticos deben prestar atención a los siguientes consejos:
- No confíes en los titulares llamativos. Aunque muchos sitios web contienen cierta información, no es necesariamente correcta. Busque siempre la fuente que respalda la afirmación y analice la metodología de los propios investigadores.
- Utilice únicamente resultados de investigación que pueda comprender en términos de contenido y que sean coherentes con su evaluación de riesgos.
- Recuerda que un incidente en tu empresa puede derivar en brechas de datos para otras empresas. Si se produce una fuga de la que su empresa es responsable, es probable que las otras partes emprendan acciones legales contra usted, aumentando su daño por el incidente.
- Tampoco olvides el caso contrario. Las violaciones de datos en socios, proveedores y contratistas sobre los que no tiene control también pueden filtrar sus datos.
Obtenga más información en el blog de Kaspersky.com
Acerca de Kaspersky Kaspersky es una empresa internacional de ciberseguridad fundada en 1997. La profunda inteligencia de amenazas y la experiencia en seguridad de Kaspersky sirven como base para soluciones y servicios de seguridad innovadores para proteger empresas, infraestructura crítica, gobiernos y consumidores en todo el mundo. La cartera de seguridad integral de la empresa incluye una protección líder para puntos finales y una variedad de soluciones y servicios de seguridad especializados para defenderse contra amenazas cibernéticas complejas y en constante evolución. Más de 400 millones de usuarios y 250.000 XNUMX clientes corporativos están protegidos por las tecnologías de Kaspersky. Más información sobre Kaspersky en www.kaspersky.com/