

C'è molto clamore sull'uso dell'intelligenza artificiale (AI) nella sicurezza informatica. La verità è che il ruolo e il potenziale dell'IA nella sicurezza è ancora in evoluzione e resta ancora molto da esplorare e valutare. un commento di Chester Wisniewski, Principal Research Scientist, Sophos.
Per sviluppare ulteriormente l'intelligenza artificiale il più rapidamente possibile e poterla utilizzare in modo ancora più efficiente in sicurezza, è particolarmente importante lo scambio completo tra ricercatori ed esperti di intelligenza artificiale. Per questo motivo, Sophos AI si impegna a condividere apertamente i risultati della sua ricerca con la comunità della sicurezza al fine di rendere più trasparente l'uso dell'IA e di contribuire attivamente alla discussione e al posizionamento dell'IA nella sicurezza informatica. Uno degli argomenti più importanti nell'ulteriore sviluppo dell'IA nella sicurezza informatica sono i diversi modelli e metodi di come l'IA apprende con dati vecchi e nuovi.
"Dimenticanza catastrofica" come modello di rilevamento AI
Il rilevamento del malware è la pietra angolare della sicurezza IT e l'intelligenza artificiale è l'unico approccio in grado di apprendere modelli da milioni di nuovi campioni di malware in pochi giorni. Tuttavia, quando si utilizza l'intelligenza artificiale per il rilevamento del malware, sorgono due domande: il modello dovrebbe conservare tutti i campioni di malware per sempre per consentire un rilevamento ottimale, anche se a scapito della velocità di apprendimento e aggiornamento? Oppure dovrebbe eseguire una messa a punto selettiva che consenta al modello di stare al passo con la velocità di cambiamento del malware, con il rischio di dimenticare i modelli precedenti? Quest'ultimo è noto come "oblio catastrofico". Oggi, la riqualificazione di un modello richiede circa una settimana. Ci vuole circa un'ora per aggiornare un buon modello di tornitura fine.
Il team AI di Sophos voleva vedere se fosse possibile progettare un modello di fine tuning in grado di tenere il passo con il panorama delle minacce in rapida evoluzione, apprendendo nuovi pattern pur ricordando i campioni più vecchi, con un impatto minimo sulle prestazioni. La ricercatrice Hillary Sanders si è occupata di questo compito e ha valutato una serie di opzioni di aggiornamento, che descrive in dettaglio nel Sophos AI Blog.
Il dilemma del riconoscimento
Mantenere aggiornato il rilevamento del malware non è un compito facile. Ad ogni passo che fai per difenderti da un attacco, i tuoi avversari rispondono con nuove idee per evitarlo. Sviluppano aggiornamenti utilizzando codice o tecniche diverse. Di conseguenza, ogni giorno emergono centinaia di migliaia di nuovi campioni di malware.
A rendere il rilevamento ancora più difficile è il fatto che raramente il malware più recente ed efficace è completamente "nuovo". Spesso è una combinazione di codice nuovo, vecchio, condiviso, preso in prestito o rubato, nonché di comportamenti adottati e adattati. Inoltre, il vecchio malware riappare anni dopo e viene integrato in nuovi metodi di attacco per cogliere di sorpresa le difese. Ergo, i modelli di rilevamento devono garantire di rilevare anche i campioni di malware meno recenti e non solo quelli più recenti.
Aggiornamento dei modelli di rilevamento AI
Quando si tratta di aggiornare i modelli di rilevamento AI con nuovi campioni di malware, i fornitori hanno due opzioni.
Option1: Mantenere ogni singolo campione e riaddestrare il modello con quantità di dati sempre maggiori. Ciò porta a migliori prestazioni complessive, ma anche a aggiornamenti più lenti e meno rilasci.
Opzione 2: Il modello di rilevamento viene aggiornato solo con nuovi campioni. Questo si chiama messa a punto. Ad ogni fase del processo di messa a punto, il modello si aggiorna con le nuove conoscenze aggiunte e con l'impatto su tutti i modelli disponibili. Di conseguenza, il modello può "dimenticare" ("oblio catastrofico") i vecchi schemi precedentemente appresi. Il vantaggio: l'addestramento di un modello con meno dati significa che può essere aggiornato e distribuito più rapidamente per tenere meglio il passo con il malware in rapida evoluzione.
Formazione continua dei modelli di riconoscimento AI
Indipendentemente dalle due opzioni menzionate, la formazione continua dei modelli di riconoscimento AI con nuovi campioni è fondamentale. Perché i modelli che un'intelligenza artificiale apprende dai campioni di malware non solo consentono il rilevamento in relazione a ciò che è stato addestrato direttamente. L'intelligenza artificiale riconosce anche campioni precedentemente sconosciuti che mostrano almeno una certa somiglianza con i dati di allenamento. Tuttavia, nel tempo, i nuovi campioni si discostano abbastanza da rendere meno efficace un vecchio modello e richiedere un aggiornamento.
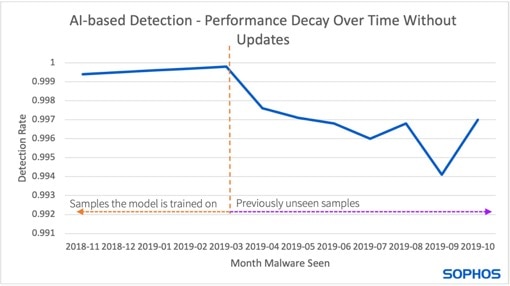
Il grafico mostra come le prestazioni di riconoscimento diminuiscono nel tempo quando i modelli non vengono aggiornati (Immagine: Sophos).
Il lato sinistro del grafico (accanto alla linea tratteggiata) mostra il modello sulla sequenza temporale con i campioni addestrati meno recenti. Qui il tasso di riconoscimento è costantemente alto. Nuovi campioni vengono aggiunti sul lato destro per i quali il modello non è stato ancora addestrato, determinando un tasso di riconoscimento inferiore.
Tre opzioni per aggiornare il rilevamento del malware
Le tre opzioni per l'aggiornamento del rilevamento del malware valutate da Hillary Sanders sono:
1. Impara con una selezione di campioni vecchi e nuovi
Questa è chiamata "prova dei dati" e prevede che un piccolo campione di vecchi campioni venga mescolato con i nuovi dati di addestramento mai visti prima. In questo modo, il modello viene "ricordato" delle vecchie informazioni di cui ha bisogno per riconoscere i modelli più vecchi, imparando allo stesso tempo a riconoscere quelli più nuovi.
2. Regolazione della velocità di apprendimento
Con questo approccio, il tasso di apprendimento del modello viene regolato. Ciò si ottiene definendo quanto il modello può cambiare dopo aver visto un particolare campione. Se il tasso di apprendimento è troppo veloce (nel qual caso il modello può cambiare molto con ogni campione aggiunto), ricorda solo i campioni più recenti. Se il tasso di apprendimento è troppo lento (il modello può cambiare solo leggermente con ogni campione aggiunto), ci vorrà troppo tempo per imparare. La difficoltà sta nel trovare il perfetto compromesso tra velocità di apprendimento, conservazione delle vecchie informazioni e aggiunta di nuove informazioni.
3. Consolidamento del peso elastico (CAE)
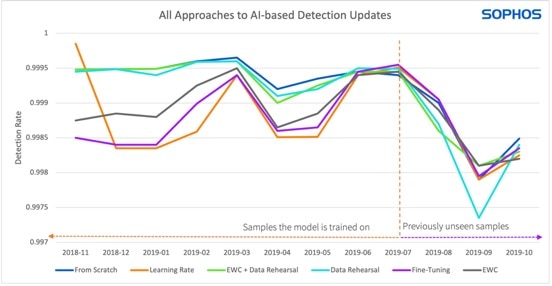
Nel grafico, tutti e tre gli approcci hanno prestazioni migliori sui campioni di malware meno recenti (a sinistra della linea tratteggiata) rispetto ai campioni più recenti, a destra della linea tratteggiata (Immagine: Sophos).
Questo approccio è stato ispirato dal lavoro di DeepMind di Google nel 2017. Come una molla elastica, tira indietro un nuovo modello su uno vecchio se inizia a "dimenticare". Hillary Sanders ha una descrizione più dettagliata di questo principio Blog SophosAI pubblicato.
Come mostrato nel grafico, tutti e tre gli approcci hanno prestazioni migliori sui campioni di malware meno recenti (a sinistra della linea tratteggiata) rispetto ai campioni più recenti (a destra della linea tratteggiata).
Conclusione
Imparare con una selezione di campioni vecchi e nuovi (prova dei dati) è il miglior compromesso
Nel rilevamento del malware, la capacità di ricordare il passato è importante quasi quanto la capacità di prevedere il futuro. Tuttavia, questo deve essere valutato rispetto al costo e alla velocità dell'aggiornamento del modello con nuove informazioni. La prova dei dati è un modo semplice ed efficace per mantenere il rilevamento del vecchio malware, aumentando notevolmente la velocità con cui è possibile aggiornare e rilasciare nuovi modelli.
Ulteriori informazioni su Sophos.com
A proposito di Sophos Sophos gode della fiducia di oltre 100 milioni di utenti in 150 paesi. Offriamo la migliore protezione contro le minacce informatiche complesse e la perdita di dati. Le nostre soluzioni di sicurezza complete sono facili da implementare, utilizzare e gestire. Offrono il costo totale di proprietà più basso del settore. Sophos offre soluzioni di crittografia pluripremiate, soluzioni di sicurezza per endpoint, reti, dispositivi mobili, e-mail e web. C'è anche il supporto dei SophosLabs, la nostra rete globale di centri di analisi proprietari. Le sedi di Sophos sono a Boston, USA e Oxford, UK.