

साइबर सुरक्षा में आर्टिफिशियल इंटेलिजेंस (एआई) के इस्तेमाल को लेकर काफी हाइप है। सच्चाई यह है कि सुरक्षा में एआई की भूमिका और क्षमता अभी भी विकसित हो रही है और बहुत कुछ खोजा और मूल्यांकन किया जाना बाकी है। चेस्टर विस्नियुस्की, प्रिंसिपल रिसर्च साइंटिस्ट, सोफोस की एक टिप्पणी।
जितनी जल्दी हो सके एआई को और विकसित करने और सुरक्षा में इसे और भी अधिक कुशलता से उपयोग करने में सक्षम होने के लिए, शोधकर्ताओं और एआई विशेषज्ञों के बीच व्यापक आदान-प्रदान विशेष रूप से महत्वपूर्ण है। इस कारण से, सोफोस एआई एआई के उपयोग को अधिक पारदर्शी बनाने और साइबर सुरक्षा में एआई की चर्चा और स्थिति में सक्रिय रूप से योगदान करने के लिए सुरक्षा समुदाय के साथ अपने शोध परिणामों को खुले तौर पर साझा करने के लिए प्रतिबद्ध है। साइबर सुरक्षा में एआई के आगे के विकास में सबसे महत्वपूर्ण विषयों में से एक यह है कि एआई पुराने और नए डेटा के साथ कैसे सीखता है, इसके विभिन्न मॉडल और तरीके हैं।
एआई डिटेक्शन मॉडल के रूप में "विनाशकारी भूल"
मैलवेयर का पता लगाना आईटी सुरक्षा की आधारशिला है, और एआई एकमात्र दृष्टिकोण है जो कुछ ही दिनों में लाखों नए मैलवेयर नमूनों से पैटर्न सीख सकता है। हालांकि, मैलवेयर का पता लगाने के लिए एआई का उपयोग करते समय, दो प्रश्न उठते हैं: क्या मॉडल को इष्टतम पहचान को सक्षम करने के लिए सभी मैलवेयर नमूनों को हमेशा के लिए रखना चाहिए - भले ही सीखने और अद्यतन करने की गति की कीमत पर? या इसे चयनात्मक फ़ाइन-ट्यूनिंग करनी चाहिए जो मॉडल को मैलवेयर के बदलाव की दर के साथ बेहतर बनाए रखने की अनुमति देती है—पुराने पैटर्न को भूलने के जोखिम पर? उत्तरार्द्ध को "विनाशकारी भूलने" के रूप में जाना जाता है। आज, एक मॉडल को पुनः प्रशिक्षित करने में लगभग एक सप्ताह लगता है। अच्छे फाइन-टर्निंग मॉडल को अपडेट करने में लगभग एक घंटे का समय लगता है।
सोफोस एआई टीम यह देखना चाहती थी कि क्या एक फाइन-ट्यूनिंग मॉडल डिजाइन करना संभव है जो तेजी से विकसित हो रहे खतरे के परिदृश्य के साथ बना रह सके, पुराने नमूनों को याद करते हुए नए पैटर्न सीख सके, कम से कम प्रदर्शन प्रभाव के साथ। शोधकर्ता हिलेरी सैंडर्स ने इस कार्य को लिया और कई अद्यतन विकल्पों का मूल्यांकन किया, जिसका वर्णन उन्होंने सोफोस एआई ब्लॉग में विस्तार से किया है।
मान्यता की दुविधा
मैलवेयर का पता लगाना अद्यतित रखना कोई आसान काम नहीं है। हमले के खिलाफ खुद को बचाने के लिए आप जो भी कदम उठाते हैं, आपके विरोधी इससे बचने के लिए नए विचारों के साथ प्रतिक्रिया करते हैं। वे विभिन्न कोड या तकनीकों का उपयोग करके अपडेट विकसित करते हैं। परिणामस्वरूप, हर दिन सैकड़ों-हजारों नए मैलवेयर के नमूने सामने आते हैं।
पता लगाना और भी कठिन बना देता है तथ्य यह है कि नवीनतम और सबसे प्रभावी मैलवेयर शायद ही कभी "नया" होता है। यह अक्सर नए, पुराने, साझा, उधार या चोरी किए गए कोड के साथ-साथ अपनाए गए और अनुकूलित व्यवहारों का संयोजन होता है। इसके अलावा, पुराने मैलवेयर वर्षों बाद फिर से प्रकट होते हैं और सुरक्षा को आश्चर्यचकित करने के लिए नए हमले के तरीकों में एकीकृत होते हैं। एर्गो, डिटेक्शन मॉडल को यह सुनिश्चित करना चाहिए कि वे पुराने मैलवेयर नमूनों का भी पता लगाएं, न कि केवल नवीनतम का।
एआई डिटेक्शन मॉडल को अपडेट करना
जब एआई डिटेक्शन मॉडल को नए मैलवेयर नमूनों के साथ अपडेट करने की बात आती है, तो विक्रेताओं के पास दो विकल्प होते हैं।
Option1: हर एक नमूने को रखना और डेटा की बढ़ती मात्रा के साथ मॉडल को फिर से प्रशिक्षित करना। इससे समग्र प्रदर्शन बेहतर होता है, लेकिन धीमी अपडेट और कम रिलीज़ भी होती हैं।
विकल्प 2: पहचान मॉडल केवल नए नमूनों के साथ अद्यतन किया जाता है। इसे फाइन ट्यूनिंग कहा जाता है। फाइन-ट्यूनिंग प्रक्रिया के प्रत्येक चरण में, मॉडल नए जोड़े गए ज्ञान और सभी उपलब्ध पैटर्न पर प्रभाव के साथ अद्यतन होता है। नतीजतन, मॉडल पहले सीखे गए पुराने पैटर्न को "भूल" ("विनाशकारी भूल") कर सकता है। लाभ: कम डेटा वाले मॉडल को प्रशिक्षित करने का अर्थ है कि इसे तेजी से बदलते मैलवेयर के साथ बेहतर ढंग से बनाए रखने के लिए अद्यतन और अधिक तेज़ी से तैनात किया जा सकता है।
एआई मान्यता मॉडल का निरंतर प्रशिक्षण
उल्लिखित दो विकल्पों के बावजूद, नए नमूनों के साथ एआई मान्यता मॉडल का निरंतर प्रशिक्षण महत्वपूर्ण है। क्योंकि एआई मैलवेयर के नमूनों से जो पैटर्न सीखता है, वह न केवल सीधे प्रशिक्षित किए गए के संबंध में पता लगाने में सक्षम होता है। एआई पहले के अज्ञात नमूनों को भी पहचानता है जो प्रशिक्षण डेटा के लिए कम से कम एक निश्चित समानता दिखाते हैं। हालांकि, समय के साथ, नए नमूने पुराने मॉडल को कम प्रभावी बनाने के लिए पर्याप्त रूप से विचलित हो जाते हैं और अद्यतन करने की आवश्यकता होती है।
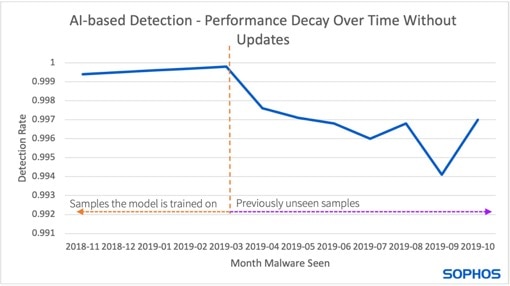
चार्ट दिखाता है कि जब मॉडल अपडेट नहीं होते हैं तो मान्यता प्रदर्शन समय के साथ कैसे घटता है (छवि: सोफोस)।
ग्राफ के बाईं ओर (धराशायी रेखा के बगल में) पुराने प्रशिक्षित नमूनों के साथ मॉडल को समयरेखा पर दिखाता है। यहां मान्यता दर लगातार उच्च है। नए नमूने दाईं ओर जोड़े जाते हैं जिसके लिए मॉडल को अभी तक प्रशिक्षित नहीं किया गया है, जिसके परिणामस्वरूप पहचान दर कम होती है।
मालवेयर डिटेक्शन को अपडेट करने के लिए तीन विकल्प
हिलेरी सैंडर्स द्वारा मूल्यांकन किए गए मालवेयर डिटेक्शन को अपडेट करने के लिए तीन विकल्प हैं:
1. पुराने और नए नमूनों के चयन के साथ सीखें
इसे "डेटा रिहर्सल" कहा जाता है और इसमें पुराने नमूनों के एक छोटे से नमूने को नए, पहले कभी नहीं देखे गए प्रशिक्षण डेटा के साथ मिलाया जाता है। इस तरह, मॉडल को पुरानी जानकारी का "याद" किया जाता है, जिसे पुराने पैटर्न को पहचानने की जरूरत होती है, जबकि साथ ही नए लोगों को पहचानना सीखना होता है।
2. सीखने की गति को समायोजित करना
इस दृष्टिकोण के साथ, मॉडल की सीखने की दर को समायोजित किया जाता है। यह परिभाषित करके पूरा किया जाता है कि किसी विशेष नमूने को देखने के बाद मॉडल कितना बदल सकता है। यदि सीखने की दर बहुत तेज़ है (जिस स्थिति में मॉडल जोड़े गए प्रत्येक नमूने के साथ बहुत कुछ बदल सकता है), तो यह केवल सबसे हाल के नमूनों को याद रखता है। यदि सीखने की दर बहुत धीमी है (प्रत्येक जोड़े गए नमूने के साथ मॉडल केवल थोड़ा बदल सकता है), तो सीखने में बहुत समय लगेगा। सीखने की दर, पुरानी जानकारी को बनाए रखने और नई जानकारी जोड़ने के बीच सही समझौता करने में कठिनाई हो रही है।
3. लोचदार वजन समेकन (EWC)
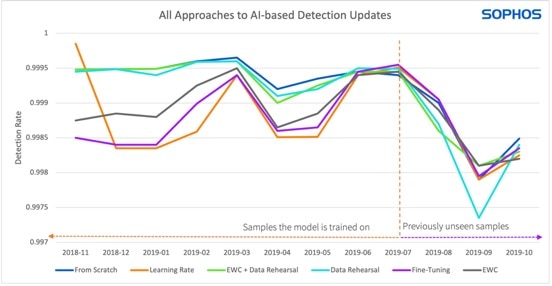
चार्ट में, सभी तीन दृष्टिकोण नए नमूनों की तुलना में पुराने मैलवेयर नमूनों (धराशायी रेखा के बाईं ओर) पर बेहतर प्रदर्शन करते हैं - धराशायी रेखा के दाईं ओर (छवि: सोफोस)।
यह दृष्टिकोण 2017 में Google के डीपमाइंड के काम से प्रेरित था। एक लोचदार वसंत की तरह, यह एक पुराने मॉडल पर एक नया मॉडल वापस खींचता है जिसे इसे "भूलना" शुरू करना चाहिए। हिलेरी सैंडर्स ने इस सिद्धांत का अधिक विस्तृत विवरण दिया है सोफोसएआई ब्लॉग प्रकाशित किया।
जैसा कि ग्राफ़ में दिखाया गया है, तीनों दृष्टिकोण नए नमूनों (धराशायी रेखा के दाईं ओर) की तुलना में पुराने मैलवेयर नमूनों (धराशायी रेखा के बाईं ओर) पर बेहतर प्रदर्शन करते हैं।
Fazit
पुराने और नए नमूनों के चयन (डेटा रिहर्सल) के साथ सीखना सबसे अच्छा समझौता है
मैलवेयर का पता लगाने में, अतीत को याद रखने की क्षमता लगभग उतनी ही महत्वपूर्ण है जितनी कि भविष्य की भविष्यवाणी करने की क्षमता। हालाँकि, इसे नई जानकारी के साथ मॉडल को अपडेट करने की लागत और गति के विरुद्ध तौला जाना चाहिए। डेटा पूर्वाभ्यास पुराने मालवेयर का पता लगाने का एक सरल और प्रभावी तरीका है, साथ ही उस गति को महत्वपूर्ण रूप से बढ़ाता है जिस पर आप नए मॉडल को अपडेट और रिलीज़ कर सकते हैं।
Sophos.com पर और जानें
सोफोस के बारे में सोफोस पर 100 देशों में 150 मिलियन से अधिक उपयोगकर्ता भरोसा करते हैं। हम जटिल आईटी खतरों और डेटा हानि के विरुद्ध सर्वोत्तम सुरक्षा प्रदान करते हैं। हमारे व्यापक सुरक्षा समाधानों को तैनात करना, उपयोग करना और प्रबंधित करना आसान है। वे उद्योग में स्वामित्व की सबसे कम कुल लागत की पेशकश करते हैं। सोफोस पुरस्कार विजेता एन्क्रिप्शन समाधान, एंडपॉइंट, नेटवर्क, मोबाइल डिवाइस, ईमेल और वेब के लिए सुरक्षा समाधान प्रदान करता है। मालिकाना विश्लेषण केंद्रों के हमारे वैश्विक नेटवर्क सोफोसलैब्स से भी समर्थन प्राप्त है। सोफोस का मुख्यालय बोस्टन, यूएसए और ऑक्सफोर्ड, यूके में है।